kaksha.dev
CPU Scheduling
Objective: To maximize CPU utilization and throughput while minimizing response time, turnaround time, and waiting time.
Key Tasks:
- Select a process from the ready queue and allocate the CPU to it.
- Balance system responsiveness and efficiency.
- Ensure fairness and prevent starvation.
Scheduling Criteria
- CPU Utilization: Keep the CPU busy as much as possible.
- Throughput: Number of processes that complete their execution per time unit.
- Turnaround Time: Time taken to complete a process from submission to termination.
- Waiting Time: Total time a process spends waiting in the ready queue.
- Response Time: Time taken to respond to a request.
Scheduling Metrics
- CPU Utilization:
- Fraction of time the CPU is busy.
- Utilization = 1 - (Idle Time / Total Time)
- Throughput:
- Number of processes completed per unit time.
- Throughput = Number of processes / Total Time
- Average Waiting Time:
- Average time a process spends waiting in the ready queue.
- Waiting Time = Total Waiting Time / Number of Processes
- Average Completion Time:
- Average time taken to complete a process.
- Completion Time = Total Completion Time / Number of Processes
Some common CPU Scheduling formulas
- Turnaround Time = Completion Time - Arrival Time
- Waiting Time = Turnaround Time - Burst Time
- Response Time = Time of first response - Arrival Time
Common Strategies
- Assign task to CPU when it becomes available.
- Preempt a task if a higher priority task arrives.
- Preempt a task if it exceeds its time quantum.
- Preempt a task if it blocks.
- Assign a simple task first.
- Assign a task that will finish soon.
- Assign a complex task first.
Scheduling Algorithms
- First-Come, First-Served (FCFS):
- Processes are scheduled in the order they arrive.
- Simple to implement
- Leads to “convoy effect” (short process behind long process)
- Shortest Job First(SJF):
- Process with the smallest execution time is selected first.
- Minimizes average waiting time.
- Disadvantage: Requires knowledge of burst times in advance and prone to starvation of long processes.
- Preemptive SJF / Shortest Remaining Time First (SRTF):
- Current process can be preempted / interrupted if a new process arrives with a shorter burst time.
- Better responsiveness and average waiting time.
- Increases overhead due to context switching.
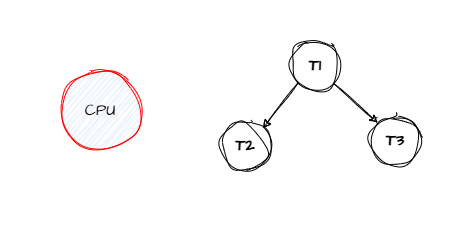
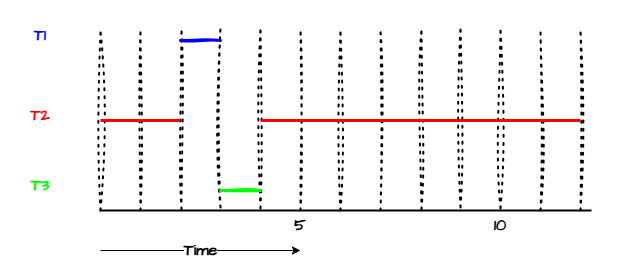
- Priority Scheduling:
- Each process is assigned a priority.
- Process with the highest priority is selected first.
- Disadvantage: Starvation of low priority processes.
- Priority Inversion & Priority Inheritance:
- Priority Inversion occues when a high priority process is waiting for a lower priority process to release a resource, but the lower priority process is preempted by a medium priority process.
Example:
- Low-priority process (P1) holds a mutex (lock).
- High-priority process (P2) is waiting for the mutex.
- A medium-priority process (P3) keeps running, preempting P1.
- This prevents P1 from releasing the mutex, causing P2 to wait indefinitely.
Solution -> Priority Inheritance:
- The priority of the lower priority process is temporarily raised to match that of the higher priority waiting process.
How it works:
- When P2 (high priority) waits for a mutex held by P1, P1’s priority is boosted to match P2’s.
- P1 completes and releases the resource.
- P1’s priority is restored to its original level.
Mutex and Priority Handling
- Mutexes often have mechanisms like priority ceiling or priority inheritance to avoid priority inversion.
- In priority ceiling protocols, a task that locks a mutex automatically inherits the highest priority associated with that mutex.
- This ensures:
- Quick access to critical sections.
- Minimal chances of priority inversion.
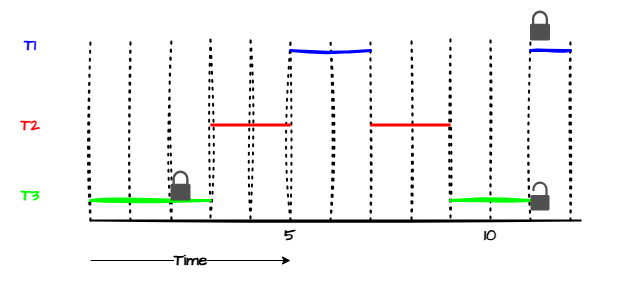
Why Mutexes Have the Largest Priority:
- Mutex locks protect critical resources.
- Giving mutex operations the highest priority ensures:
- Swift acquisition and release of resources.
- Avoidance of deadlocks and bottlenecks in high-priority tasks.
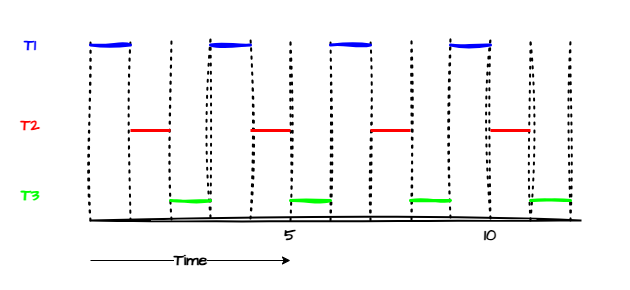
- Round Robin (RR):
- Each process is assigned a fixed time slice (time quantum).
- Process is preempted if it exceeds its time quantum.
- Fair and prevents starvation.
- Disadvantage: Too small of a time quantum increases the context switching overhead, too large of a time quantum leads to FCFS.
- Multilevel Queue Scheduling:
- Processes are divided into multiple queues based on their type or priority (e.g., system processes, interactive processes, batch processes).
- Each queue has its own scheduling algorithm.
- Queues are scheduled in a priority order.
- Multilevel Feedback Queue Scheduling:
Issues with Multilevel queue were that,
- How to know which queue to put a process in?
- What happens if a task changes its behavior?
- How to prevent starvation?
- How to know if a task is CPU-bound or I/O-bound?
Solution -> Multilevel Feedback Queue Scheduling:
- Add the task to the highest priority queue.
- If the task uses its entire time quantum, it is moved to a lower priority queue.
- Boost the priority of a task that waits for a long time.
- This makes sure that processes can move between queues are not stuck in a rigid structure, and can be scheduled based on their behavior.
O(1) Linux Scheduler
Designed to select the next process to run in O(1) constant time, regardless of the number of processes in the system.
Key Features:
- Each CPU has its own runqueue.
- Each runqueue has two priority arrays:
- Active array: Contains processes that are ready to run.
- Expired array: Contains processes that have used up their time quantum.
- Processes are prioritized into 140 levels:
- 0-99: Real-time tasks (higher priority).
- 100-139: Normal tasks (lower priority).
- Higher priority tasks get more CPU time and lower priority tasks get less CPU time.
- Processes in the expired array are moved to the active array when:
- The active array is empty.
- The time quantum of the current process expires.
- A higher priority process arrives.
O(1) Scheduler Algorithm:
- Select the highest priority process from the active array.
- If the active array is empty, swap the active and expired arrays.
- If the expired array is empty, select the highest priority process from the active array.
- If the active array is still empty, select the idle task.
Issues:
- Not fair to lower priority tasks.
- Difficult to perform interactive tasks.
CFS (Completely Fair Scheduler)
Designed to provide fairness whilst maintaining efficiency.
Fairness Concept
- Based on proportional share scheduling, where each process gets CPU time proportional to its weight (priority).
Virtual Runtime
- Trackes the CPU time a process should have received.
- Lower vruntime means higher priority for scheduling
Red-Black Tree
- Processes are stored in a balanced red-black tree, ordered by vruntime.
- The leftmost node has the smallest vruntime and is selected first.
Dynamic Priority Adjustment
- Interactive processes (lower in CPU usage) tend to have a lower vruntime, ensuring quick response times.
- CPU-bound processes (higher in CPU usage) tend to have a higher vruntime, ensuring fairness.
CFS Algorithm:
- Select the leftmost node from the red-black tree.
- Update the vruntime of the selected process.
- Rebalance the tree if necessary.
Issues: High overhead due to red-black tree operations. -> O(log n)
Multi-Core & Multi-CPU Scheduling & Simultaneous Multi-Threading (SMT)
Shared Memory Architecture:
- All processors share the same physical memory.
- Ensures efficient inter-core communication but requires careful synchronization.
Scheduling Challenges:
- Load Balancing: Ensure workload is evenly distributed across all cores to maximize CPU utilization.
- Process Affinity: Optimize for processes running on the same core (to benefit from cache locality).
- Contention Management: Minimize bottlenecks caused by processes competing for shared resources.
Scheduling Strategies:
Global Scheduling:
- A single runqueue for all CPUs.
- Processes can migrate between cores to balance load.
- Advantage: Better load balancing.
- Disadvantage: Higher overhead due to inter-core communication.
Per-Core Scheduling:
- Each core has its own runqueue.
- Advantage: Low contention and simpler implementation.
- Disadvantage: Potential for uneven load distribution.
Hybrid Scheduling:
- Combines global and per-core scheduling for improved scalability and performance.
Processor Affinity:
Soft Affinity:
- Scheduler prefers to keep processes on the same core but may migrate them for load balancing.
Hard Affinity:
- Processes are strictly bound to specific cores.
Simultaneous Multithreading (SMT):
- A technique that allows a single CPU core to execute multiple threads simultaneously by sharing its execution units.
- Better utilization of CPU resources.
- Higher throughput for multithreaded workloads.
- Thread scheduling must ensure fair resource sharing and avoid performance degradation due to contention.
Cache Affinity in CPU Scheduling
Keep tasks running on the same CPU to maximize cache hits and minimize cache misses.
- Improves performance by reusing cached data.
- Reduces overhead from reloading data into the cache.
Locality-Based Scheduling:
- Scheduler attempts to keep tasks bound to the CPU they previously ran on.
Load Balancing (LB):
- Distributes workloads across CPUs to prevent idle cores.
- Balancing is based on:
- Queue Length: Number of tasks in a CPU’s runqueue.
- CPU Idle Time: Cores with more idle time get more tasks.
A load balancer and scheduler work together to ensure optimal CPU utilization and cache affinity.
RAM Affinity in CPU Scheduling
Optimize memory access speed by assigning tasks to CPUs closer to the RAM node containing their data.
NUMA (Non-Uniform Memory Access):
- System architecture where multiple memory nodes are linked to specific CPUs.
- Local Memory Access: Faster when a CPU accesses its directly connected memory.
- Remote Memory Access: Slower when accessing RAM from a different node.
Task Placement:
- Scheduler tries to keep tasks on CPUs closer to the memory they frequently use.
- Reduces latency and improves performance.
NUMA-Aware Scheduling:
- Scheduler considers memory locality when assigning tasks to CPUs.
- Balances performance and fairness by avoiding unnecessary cross-node memory access.
Load Balancing:
- Still essential to ensure all CPUs are utilized efficiently.
- Balances workload without sacrificing memory locality.
Hyper-Threading (HT) in CPUs
Hardware multithreading technique where a single CPU core executes multiple threads simultaneously by sharing resources like ALUs and caches.
Execution Context with Registers: Each thread has its own set of registers to store the execution context, enabling quick switching.
Hardware Multithreading:
- Simultaneous Multithreading (SMT): Multiple threads executed simultaneously on a single core.
- Can be disabled in BIOS for specific use cases.
CMT vs SMT:
- CMT (Chip Multithreading): Multiple cores, each handling a single thread.
- SMT: Single core running multiple threads using shared resources.
Hides Memory Latency: When one thread stalls (e.g., waiting for memory), another thread can utilize the CPU.
Performance Optimization:
- Use hyper-threading if idle time exceeds 2x context switch time to ensure efficiency.
- Optimize based on IPC (Instructions Per Cycle): Measures how effectively a CPU is utilized.
Task Allocation:
- Best performance occurs when:
- One thread handles a compute-bound task (e.g., heavy calculations).
- The other thread handles a memory-bound task (e.g., data fetching).
How to know a task is CPU or Memory Bound?
-
Historical Data: Analyze previous execution patterns to determine if the task heavily uses CPU or memory.
- Metrics Like Sleep Time:
- CPU-bound: Minimal sleep time, as the task continuously utilizes the CPU.
- Memory-bound: Longer waiting periods, though not always sleeping, due to memory access delays.
- Performance Observations:
- Tasks taking too long to compute are likely CPU-bound.
- Tasks stalling due to data fetching or memory access are memory-bound.
- Hardware Counters:
- Cache Misses (L1, L2, LLC): High misses indicate memory-bound tasks.
- IPC (Instructions Per Cycle): Low IPC often signals a memory-bound task.
- Power/Energy Consumption: Patterns help differentiate between CPU-intensive and memory-intensive tasks.
- Linux Profiling Tools (Softwares)